AVL Exploitation System Design#
Software Components Design – Exploitation System#
Every laboratory makes use of standard procedures and standard measures to make any syntheses and analyses reproducible, traceable, comparable, and effective. A data exploitation laboratory is no exception. We provide the majority of AVL data in a standardised, analysis-ready form to users. The core idea is to let users interact with uniform multi-dimensional, multi-variate data cubes, whose internal data arrays are subdivided into smaller chunks. These chunks are stored in a cloud-ready format and can be read, processed, and written independently in a concurrent fashion. The chunked structure of data cubes facilitates scalable, massively parallel data analyses, allows for on-the-fly processing when only subsets of data are requested. All cubes preserve the original metadata of data products and variables and maintain them in a CF-compliant way.
AVL provides numerous ready-to-use data cubes to users. These comprise a set of commonly used spatio-temporal coverages and resolutions for a given sensor and/or use case. Upon user demand, EO and non-EO data sources and formats data cubes may be produced either on-the-fly or persistent into cloud object storage. For this purpose, we use the open source xcube toolkit developed by BC. xcube builds on the popular Python data science packages xarray, dask, pandas and others. By doing to, it shares a common architectural and implementation basis with other data cube systems such as Pangeo and Open Data Cube.
Within xcube, any data source is represented by an xcube datastore implementation. A datastore abstracts from the individual data provision method and data formats. It allows creating data cube views from any suitable data source. To foster multi-variate analyses, gridded EO- and non-EO data as well as EO data in satellite (viewing) geometry can be resampled to user-provided spatio-temporal resolution grids. This process is transparent to the user and may include global or local cartographic projections, down-sampling (aggregating original values), and up-sampling (interpolating between original values). The responsible xcube datastore implements the best respective method for a given data variable.
By using the xcube Python SDK in a Jupyter Notebook, user can directly open data cubes and start interacting with the data. It remains transparent to the user whether a data cube has been opened from a persistent instance or whether it is generated on the fly, e.g. by delegating its data requests to another data provider such as Sentinel Hub. Apart from the Python SDK, the xcube toolkit comprises powerful command-line tools for generating, maintaining, and exploiting data cubes. xcube also provides convenient and intuitive web apps. The xcube Viewer app is used to visualise data cubes and time series.
In addition to these web apps, we will utilise the ESA CCI Toolbox Cate for AVL. This Toolbox has been developed for the multi-variate, cross-ECV exploitation of the ESA CCI datasets. Originally planned to run on users' computers, Cate has been recently turned into a Software-as-Service, comprising an attractive web GUI and a backend that shares the same Python package stack as xcube.
In-situ data, and other geo-referenced data, that are not made available via public, standardized web services will be persisted in a dedicated database, the geoDB system, which has been developed specifically for this purpose. The geoDB has a comprehensive and intuitive Python client SDK so users can manipulate and access geo-data from their Python programs and Jupyter Notebooks. A dedicated xcube datastore allows for creating data cube views from geo-referenced vector data stored in geoDB. This enables the mapping of vector and feature data into the same coordinate space as a given EO data cube, e.g. for machine learning tasks or for masking gridded EO data with vector shapes.
In summary, the exploitation sub-system of AVL comprises the following parts and top-level-entry points:
-
AVL Juypter Notebooks – to read, visualise, analyse, process, write AVL cubes using Python,
-
AVL Cube Viewer – to quickly inspect and visualise all AVL cubes and time series,
-
AVL Cube Toolbox – to read, visualise, analyse, process, write AVL cubes using a powerful GUI.
The following diagram details the AVL Exploitation subsystem whose components are described hereafter:
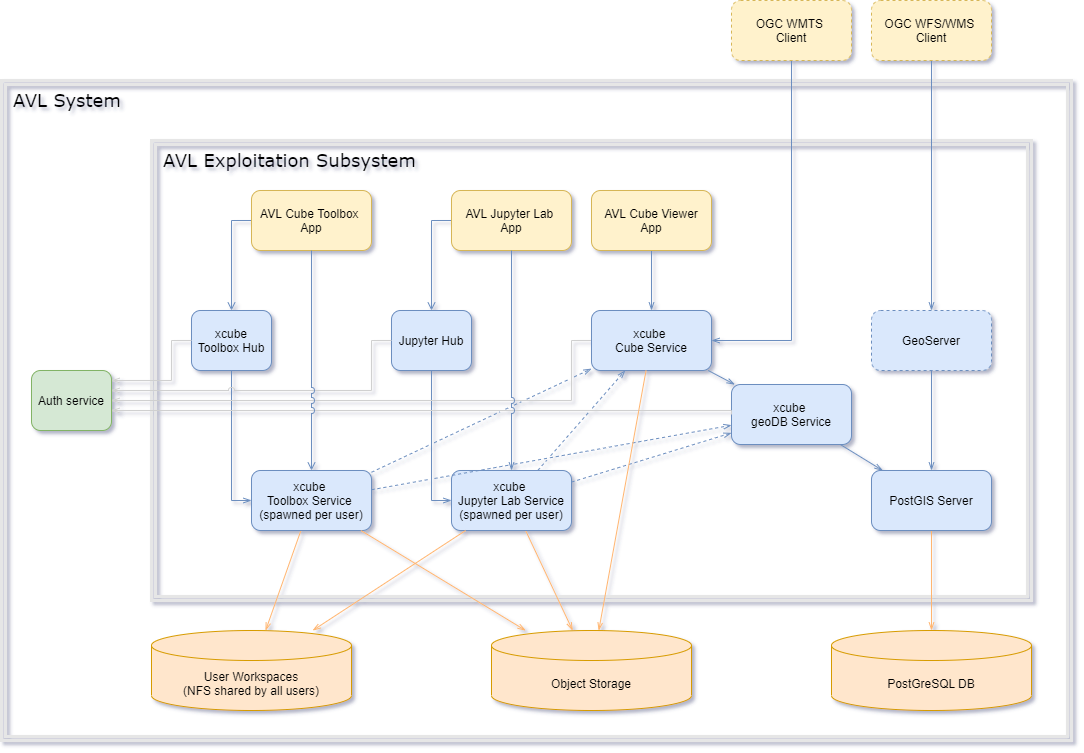 AVL Exploitation Subsystem
AVL Exploitation Subsystem
AVL Toolbox App#
General#
The AVL Toolbox App is a web application that is used to visualize, analyse, and process the AVL data cubes from Object Storage, from users' own workspaces, and from external data sources.
Function#
The AVL Toolbox App comprises numerous functions for analysis and processing. Given here are high-level ones:
-
Browse data stores,
-
Browse datasets from data stores, search datasets, inspect datasets details,
-
Open datasets,
-
Browse available (Python) functions, search functions, inspect functions details,
-
Apply (Python) functions to datasets or data to generate new datasets or other data,
-
Store sequence of applied functions as workflow in the user's workspace,
-
Change parameters of a function in the workflow and re-execute,
-
Visualize rich set of different plots (for functions outputting figures),
-
Visualize datasets one or more 3D globes,
-
Overlay multiple variables in one view and split views,
-
Display gridded data and vector data,
-
Browse a dataset's variables, inspect variable details,
-
Upload/download data to/from user workspace, browse user workspace.
Dependencies#
The AVL Toolbox app depends on the AVL Toolbox Hub and the AVL Toolbox services spawned by the Hub for each logged in user.
Interfaces#
The AVL Toolbox app is a progressive, single page web application that runs in any modern browser.
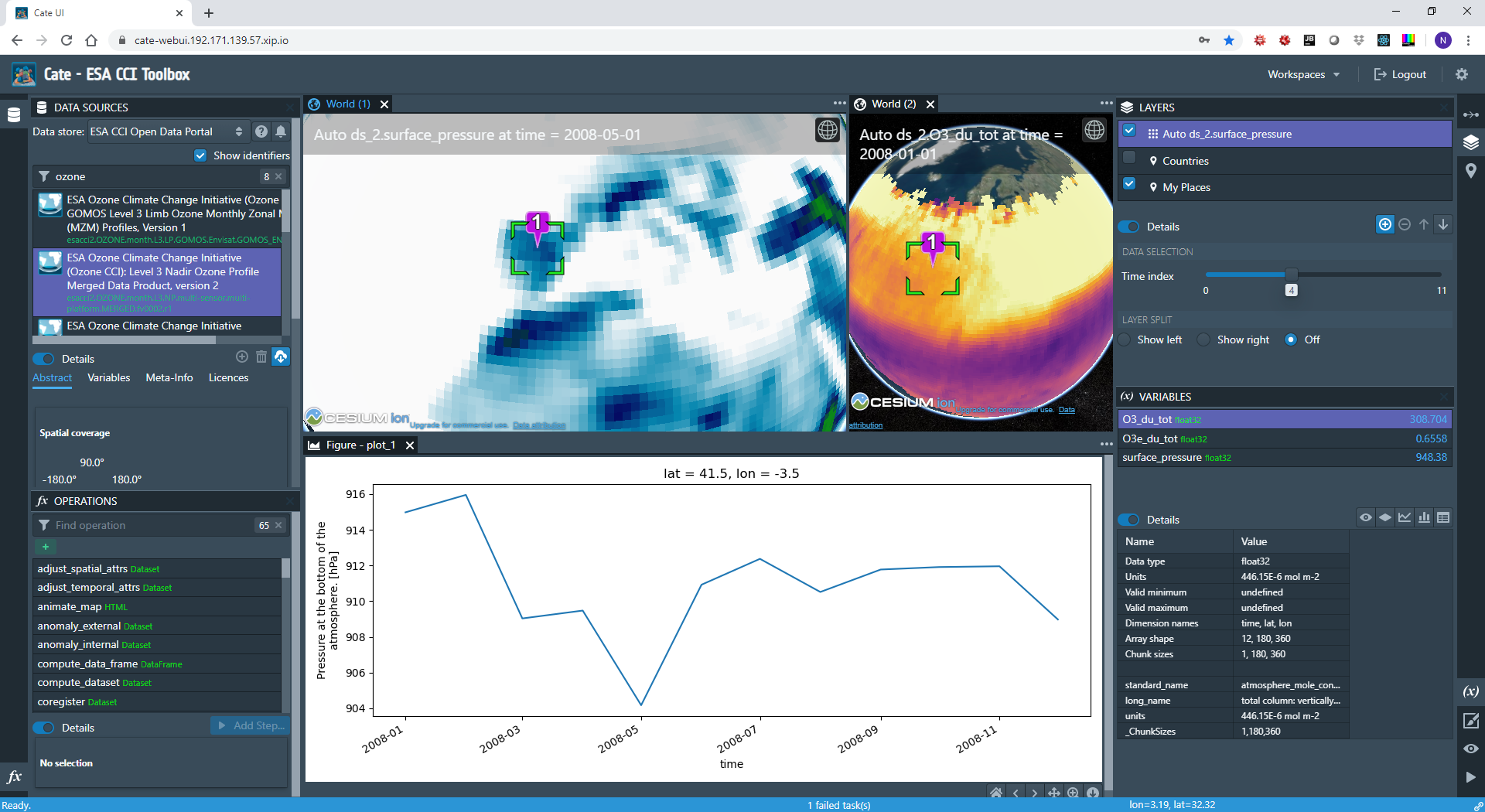 AVL Cube Toolbox user interface
AVL Cube Toolbox user interface
AVL Toolbox app is programmed in TypeScript and is using the popular React, BlueprintJS, and Cesium JavaScript libraries.
xcube Toolbox Hub#
General#
The xcube Toolbox Hub is a web service whose main responsibility is spawning new xcube Toolbox services for each logged-in user. For authenticated users, the service assigns a workspace directory (user home directory) and runs a dedicated toolbox service bound to that workspace.
Function#
-
Associate workspace directory with user,
-
Spawn new xcube services per user,
-
Auto-shutdown idle user services,
-
Limit concurrent services,
Dependencies#
The xcube Toolbox Hub depends on the Auth service. It also requires Kubernetes to spawn and manage xcube Toolbox services.
Interfaces#
The xcube Toolbox Hub has a dedicated REST API that is used by the xcube Toolbox App.
xcube Toolbox Service#
General#
The main purpose of the xcube Toolbox service is to implement and execute the AVL Toolbox App functionality. It does this on a per-user basis.
Function#
The xcube Toolbox service implements the AVL Toolbox App's functionality:
-
List data stores,
-
List datasets from data stores, search datasets, provide datasets details,
-
Open and cache datasets,
-
List a dataset's variables, provide variable details,
-
List available (Python) functions, search functions, provide functions details,
-
Invoke (Python) functions to datasets or data to generate new datasets or other data,
-
Store sequence of applied functions as workflow in the user's workspace,
-
Execute new and re-execute changed workflows,
-
Provide matplotlib backend for plot rendering,
-
Provide image tiles for on-the-fly visualization of variables of gridded datasets,
-
Provide GeoJSON streams for on-the-fly display of vector datasets,
-
Provide user workspace management (file upload/download, file tree browsing).
Dependencies#
The xcube Toolbox service depends on the following components:
-
User Workspace – to store/load user workflows, analysis results, cache datasets,
-
Object Storage – to store/load system and user dataset (data cubes in Zarr format),
-
xcube Cube Service – to ingest the system data cubes as data store
-
xcube geoDB Service – to ingest the system vector data sources as data store.
Interfaces#
The xcube Toolbox service API is based on two protocols, a REST API based on HTTP and a JSON RPC API based on WebSockets.
The REST API provides:
-
low level workspace file management like upload, download, deletion,
-
the image tiles for the variables of a gridded datasets given its colour mapping.
The JSON RPC API does anything else:
-
Listing of data stores, datasets, functions,
-
Invocation of functions, progress monitoring and cancellation of running functions,
-
Execution of user workflows, progress monitoring and cancellation of running workflows,
-
Management of user workflows: new, deletion, adding new functions calls, changing function parameterisation.
AVL Jupyter Lab App#
General#
The AVL Jupyter Lab App is a web application that allows user to create, execute and manage their Jupyter Notebooks. It is an extended and customized version of the standard JupyterLab environment, with a slightly branded UI to indicate that it belongs to the AVL system. The AVL Jupyter Lab App is regarded as the most important part of the AVL Exploitation system.
Function#
The standard functionality of the core JupyterLab is well-known and is described in its extensive documentation. The AVL Jupyter Lab uses a customized Python-based user image which includes a rich set of popular data science packages, including xarray, geopandas, dask, numpy, scipy, and numba. Additionally, it incorporates packages which extend the functionality of JupyterLab itself, including functionality to work with GitHub code repositories, visualize GeoJSON data, and explore Dask computation processes.
The AVL JupyterLab app user image also includes the xcube package and any further functionality required by AVL users. By using xcube, users can
- Ingest datasets from internal data stores:
- Datasets in AVL Object Storage
- Datasets exposed by xcube cube service
- Datasets exposed by xcube geoDB service
- Ingest datasets from various external data stores:
- Sentinel Hub,
- ESA CCI,
- C3S Climate Data Store
- Copernicus CMEMS Data Store
- Non-AVL S3 object storage
- Display and analyse data cubes
- Generate new data cubes
- Rasterize vector datasets
The AVL JupyterLab user image also provides custom integrations with the rest of the AVL system, including:
-
Predefined, preinitialized data store definitions giving the user instant, configuration-free access to the AVL's various object storage buckets and other data stores.
-
Automatic integration of a selection of introductory example notebooks which document and demonstrate the features provided by the AVL.
-
On-demand provision of dask compute clusters for users via the Coiled API.
Dependencies#
The AVL JupyterLab App depends on the Jupyter Hub and the xcube Jupyter services spawned for individual users. Initialization of the user environment depends on the pre-built custom AVL Jupyter user image. Initialization and update of the demo notebooks folder depends on the AVL demo notebook GitHub repository. The full AVL data store functionality depends on the AVL object storage resources.
Interfaces#
For user interaction, the AVL JupyterLab App uses the well-known graphical JupyterLab user interface:
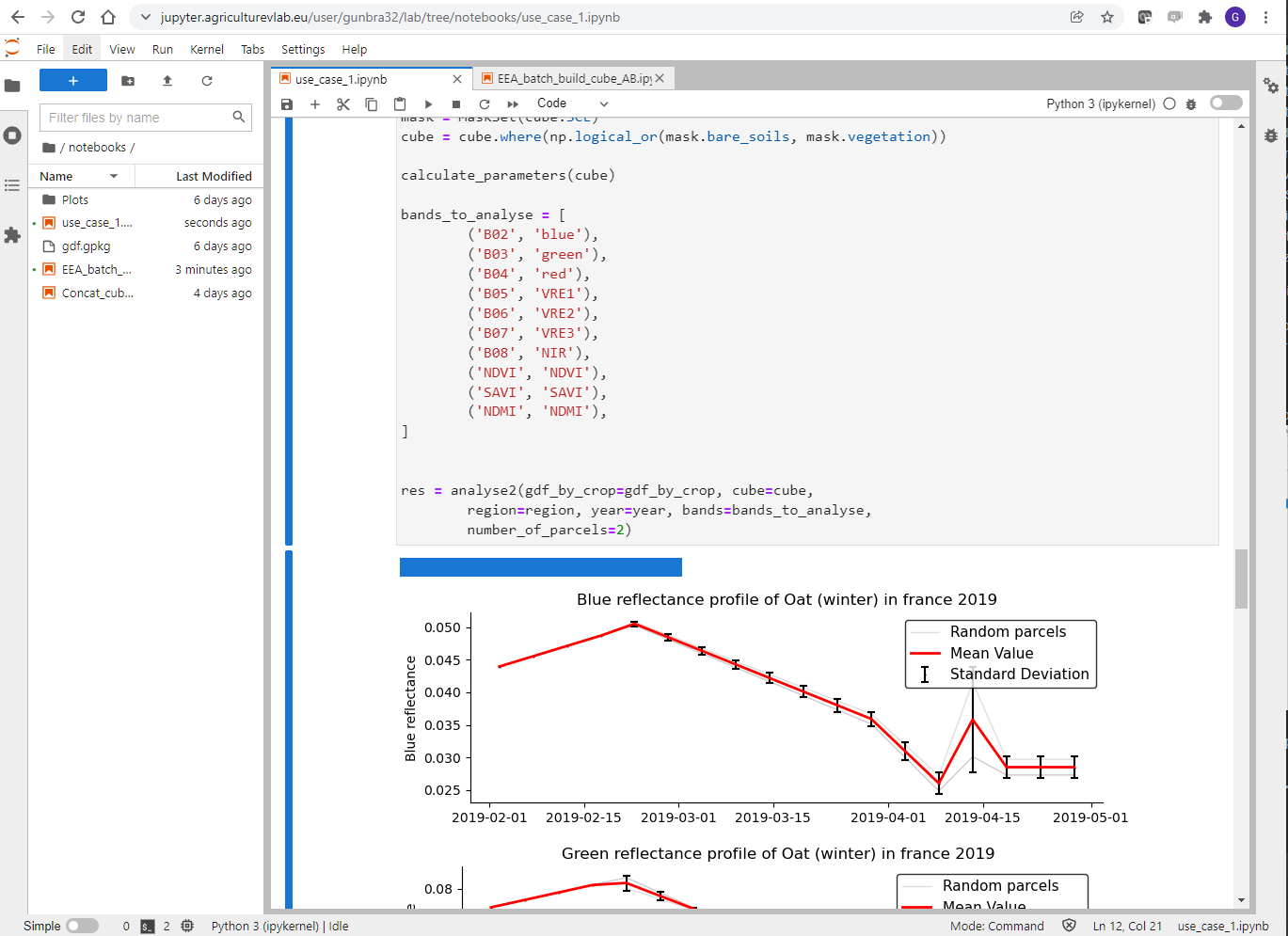 JupyterLab user interface
JupyterLab user interface
For communication with the Jupyter Hub, the JupyterLab app uses the JupyterHub API documented at https://jupyterhub.readthedocs.io/en/stable/reference/rest-api.html.
For access to object storage (including the AVL object storage buckets), the JupyterLab environment uses the S3 protocol.
For geoDB access, JupyterLab uses the geoDB API via its Python client.
xcube data stores use additional interfaces to communicate with data provider services – currently:
For cluster-as-a-service provisioning to provide additional on-demand data processing capacity, AVL uses the Coiled API to instantiate and control its resources.
Jupyter Hub#
General#
A Jupyter Hub instance in the AVL Exploitation system is responsible for spawning xcube Jupyter Lab services for individual users so that they can run their Notebooks.
The AVL Jupyter Hub uses a custom container image defined in an AVL GitHub repository in order to add some custom features to the standard JupyterHub implementation. These features are implemented in a module of the agriculture-vlab Python package, which is installed into the AVL container image.
Function#
The functionality of the Jupyter Hub comprises:
- Handle authentication in coordination with the AVL KeyCloak authentication service.
- Handle authorization via internal configuration of administrator and user privileges.
- Associate workspace directory with user.
- Spawn new xcube Jupyter services per user.
- Auto-shutdown idle user services.
- Limit concurrent services.
The additional features integrated into the custom hub container image also provide the following functionality:
-
When a user logs in via KeyCloak, ensure that a corresponding AWS IAM user exists to allow the user to access AVL object storage buckets from within the JupyterLab environment.
-
Create credentials for the user's corresponding IAM user.
-
Pass these credentials into the JupyterLab runtime as environment variables, allowing the S3 access backend to make automatic and transparent use of them.
Dependencies#
The Jupyter Hub depends on:
- The common authentication service for AVL, provided by a KeyCloak server
- A Kubernetes cluster providing the necessary computation and storage resources
- A custom JupyterHub container image
Interfaces#
For authentication via the Keycloak service, Jupyter Hub interfaces uses the OAuth2 protocol.
For initialization and monitoring of the users' JupyterLab instances, Jupyter Hub uses the jupyterhub REST API.
For managing IAM users and credentials for access to the AVL object storage buckets, Jupyter Hub uses the AWS IAM API.
xcube Jupyter Service#
General#
This is the service spawned by Jupyter Hub. It is basically the same service as the standard Jupyter Notebook service. However, for AVL, the Python kernels used comprise the xcube software, dedicated AVL functions and a large set of common data science packages as described in the AVL Jupyter Lab App component.
Function#
This is the per-user service that provides the Jupyter Lab backend:
- Launching and running kernels,
- Notebook management,
- Data up- and download.
Dependencies#
The xcube Jupyter service depends on the following components:
-
User Workspace – to store/load user data,
-
Object Storage – to store/load system and user datasets (data cubes in Zarr format),
-
xcube Cube Service – to ingest the system data cubes as data store,
-
xcube geoDB Service – to ingest the system vector data sources as data store.
Interfaces#
The xcube Jupyter service uses a well-known REST API and uses WebSockets for running and managing Notebooks.
AVL Cube Viewer App#
General#
The AVL Cube Viewer App is a simple and intuitive web application that is used to browse and visualize the AVL data cubes. It also provides basic time series analyses. Multiple time series can be easily generated for points or areas and visualised side-by-side. Points and areas my be user defined or come from a configured places library (vector data source).
Function#
With the AVL Cube Viewer App users can:
- Browse available data cubes,
- Display detailed data cube information,
- Select cube variable and display it on the map,
- Change variable colour mapping (colour bars and value range),
- Browse associated place groups and places,
- Draw user defined places such as points, circles, polygons,
- Select place group and draw it on the map,
- Select place and generate time series,
- Display multiple time-series plots side by side.
Dependencies#
AVL Cube Viewer App solely depends on xcube Cube Service.
Interfaces#
The AVL Cube Viewer App is a progressive, single page web application that runs in any modern browser.
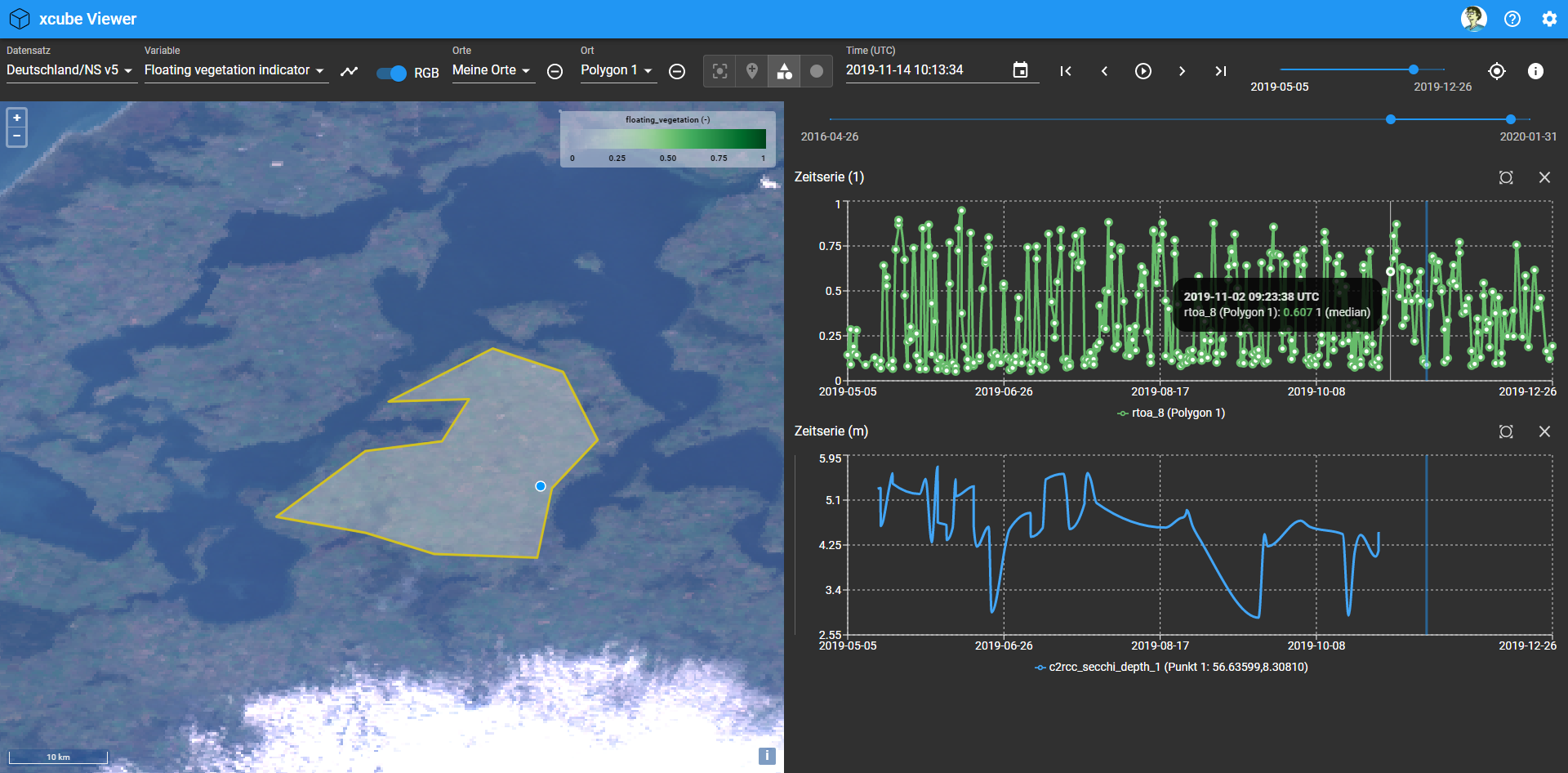 AVL Cube Viewer App user interface
AVL Cube Viewer App user interface
User wishing to use or extend the app must use its source code and recompile it. The app is programmed in TypeScript and is using the popular React, Material UI, and OpenLayers JavaScript libraries.
xcube Cube Service#
General#
The main purpose of the xcube Cube Service is to publish the AVL data cubes through a dedicated REST API. This is used by the AVL Cube Viewer App but may also be used by other AVL services such as the AVL Toolbox services and the xcube Jupyter service. The xcube Cube Service also publishes configured vector datasets ("place groups") that are associated with the data cubes.
Function#
The functions of the xcube Data Service are:
-
Data cube catalogue:
-
List AVL data cubes from Object Storage,
-
Provide detailed data cube information.
-
-
Image tiles:
-
Provide tiles for RGB images for one or more variables of a data cube,
-
Provide tiles for colour-mapped images for a variable of a data cube.
-
-
Vector data:
-
List configured place groups, e.g., from xcube geoDB Service,
-
Provide places of given place group as GeoJSON.
-
-
Time series:
-
Aggregate data variables for given place,
-
Extract time series for given place.
-
Dependencies#
The xcube Cube Service depends on the
-
Auth Service – to authenticate the user and authorize users for the API,
-
Object Storage – to ingest data cubes publish them as data store,
-
xcube geoDB Service – to ingest vector data and publish them as data store.
Interfaces#
The xcube Cube Service uses a REST API that comprises API operations for all the functions described above.
The image tile provision API is compatible with the OGC Web Map Tile Service (WMTS).
The dataset catalogue API is not yet but will be made compatible with the STAC specification.
xcube geoDB Service#
General#
The xcube geoDB service provides operations to manage geo-spatial collections comprising features – a set of properties associated with geo-spatial geometry. Users can query, create, modify, and delete collections and features.
Function#
- Query collections,
- Create, modify, and delete collections,
- Share collections with other users,
- Query features,
- Add/change/remove features to/in/from collection.
Dependencies#
The xcube geoDB Service depends on the PostGres database service.
Interfaces#
The xcube geoDB Service provides a dedicated REST API that fully covers the functionality described above.
The xcube geoDB Service also has a Python client that wraps the REST API so its functionality can be used from Jupyter Notebooks.
GeoServer#
General#
The GeoServer service is optional and may be added to add an OGC layer on top of the geo-spatial AVL collections stored in the PostGres DB and managed by the xcube geoDB Service. With GeoServer, the AVL collections can be easily exposed via OGC WFS and WMS.
Function#
The GeoServer capabilities are well-known and -documented. The functionality exploited here would be:
- Expose AVL collections via OGC WFS,
- Expose AVL collections via OGC WMS,
- View AVL collections in GeoServers own map viewer.
Dependencies#
The GeoServer would depend on the Auth service and the PostGre database.
Interfaces#
OGC WFS and OGC WMS.
Interfaces Context#
Local Data Sources#
Even if the local data source (comprising in the local database and file system) is not an external interface, it is important to lay out its organization before describing the external interfaces of the system.
As it can be seen in the below Figure, the local data source consists of a product database, in which metadata associated with concrete data products are stored, and a local (network) file system, in which the data products are physically stored.
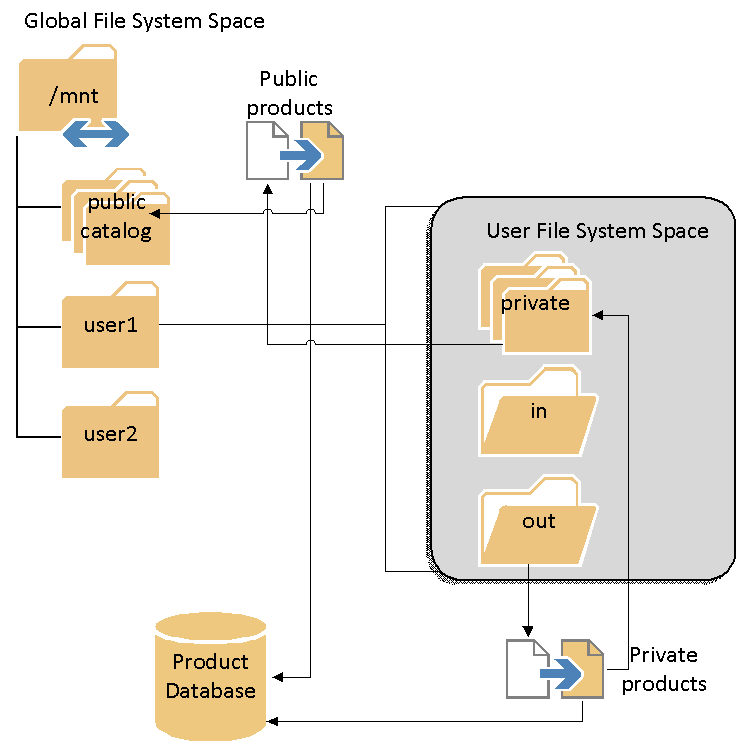 Local data (product) source
Local data (product) source
The product database stores basic metadata about the EO products, such as acquisition date, geographical footprint, product type, etc.
This metadata allows the users to query the local data source for products satisfying certain criteria and is created when either products are initially imported, or new products are downloaded from remote data sources.
The file system is organized such that an easier distinction can be made between public products (products that are visible/usable by all users) and private products (products visible/usable only by a specific user). This separation further allows the implementation of user quota management.
The visibility of the products will be implemented at a logical level (i.e., not by physical operating system rights) in the database.
The file system structure depicted above will be visible to (i.e., shared with) all the processing nodes in the AVL cluster. This is necessary in order to allow a uniform way of accessing products by processing components from remote nodes.
Interfaces with External Data Sources#
Beyond the product collection that the users may already have, there may be cases when additional EO data should be used for accomplishing the user goals. This is where the external data source components intervene. Like the local data source described in the previous paragraph, the purpose of an external data source component is to query an EO data provider and retrieve one or more data products satisfying certain user criteria.
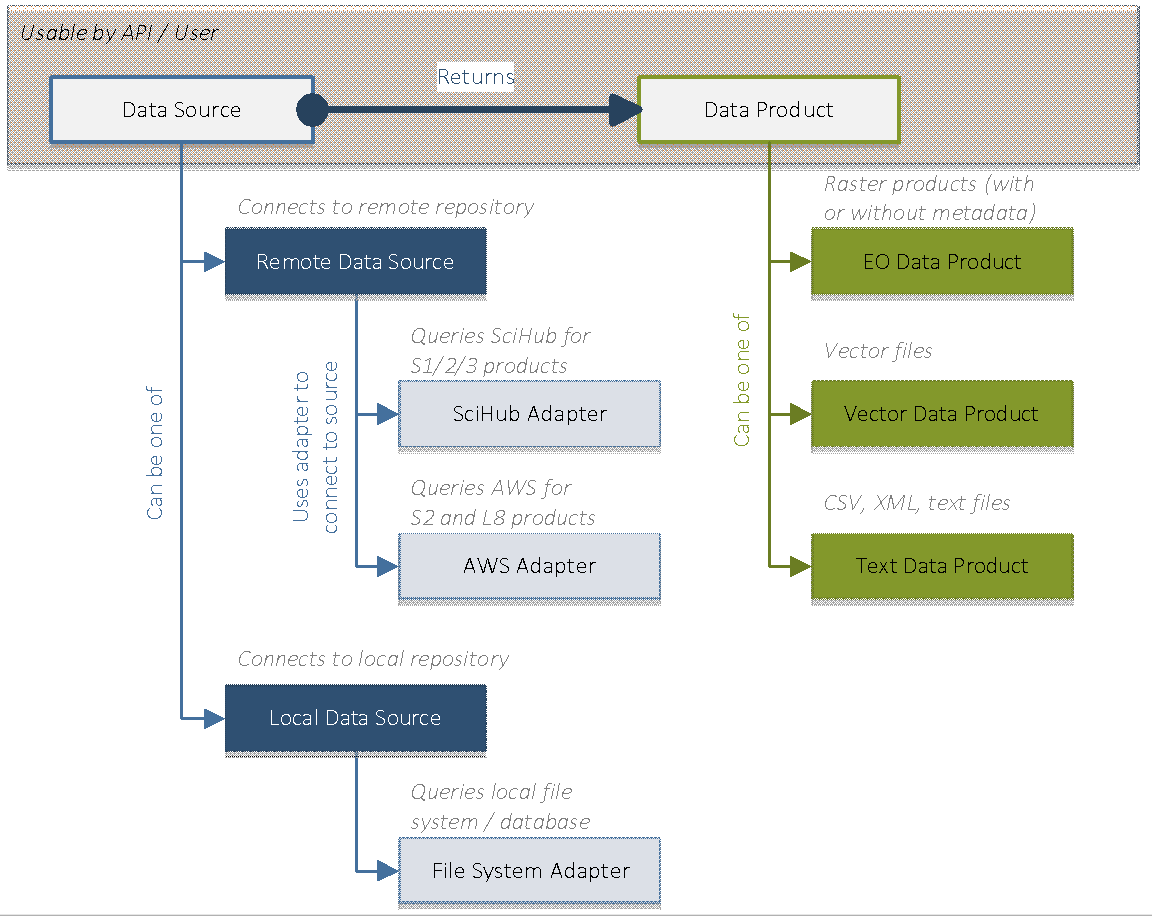 Types of data sources
Types of data sources
The two types of data sources share the same interface, for the TAO API the location of the data being transparent. It is the implementation of the data source that takes care of properly connecting to the remote repository and querying and retrieving the data products.
The data source interface should expose operations (i.e., methods) allowing to:
- Connect to the remote repository,
- Authenticate to the remote repository,
- Create a query to be executed against the repository.
Given the diversity of EO products (and product providers), the parameters of a query may be bound to a specific repository. Nevertheless, a preliminary analysis revealed that there is a small subset of parameters that are supported by different providers, namely:
- The product name or identifier,
- The acquisition date (and time),
- The product footprint.
Besides these parameters, various providers may exhibit different parameters (even if a parameter would conceptually represent the same measure, two providers may have different notations for it). In order to cope with this diversity, the query shall allow for name-value collections of parameters that will be described for each data source. This allows adding (or describing) new data sources without any impact (or change) of the object and relational model.
The next figure illustrates the above attributes and features of the data source and data query components:
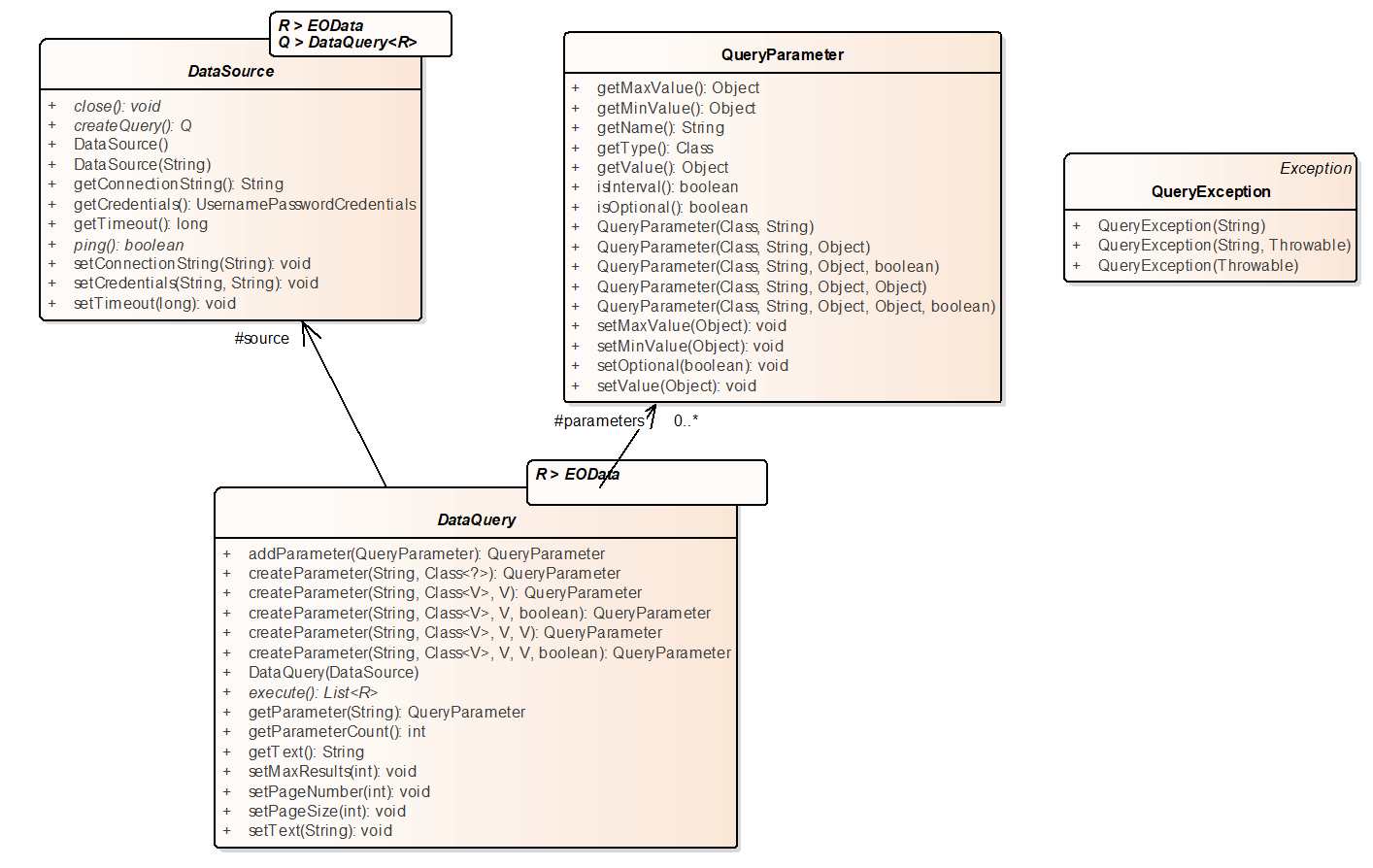 Generic data source and data query interfaces
Generic data source and data query interfaces
For the purpose of the AVL platform prototype, the external EO data providers used are based on the agreed selection from the list contained in RD.3.
Interfaces for External System Access#
A closed platform is of limited use and impales its adoption by the community. Therefore, the AVL platform allows for the interoperation with external systems, and for a standardized access by external clients. In order to accomplish that, it will rely on an OGC-compliant interface.
Interface with Cloud Computing Infrastructure#
TAO#
In order to decouple the core of the TAO framework from the actual Cluster Resource Manager implementation, the latter component will have a DRMAA-compliant interface.
The DRMAA provides a standardized access to the DRM systems for execution resources. It is focused on job submission, job control, reservation management, and retrieval of jobs and machine monitoring information.
Currently, TAO supports several DRMAA implementations, presented in the next table:
| DRMAA Implementation Language | DRM System |
|---|---|
| C | PBS/Torque |
| C | SLURM |
| Java | TAO-SSH |
| Java | Kubernetes |
List of existing DRMAA implementations
The approach adopted by the TAO framework will allow for easily swapping such implementations, making the framework loosely coupled from the actual DRM system used.
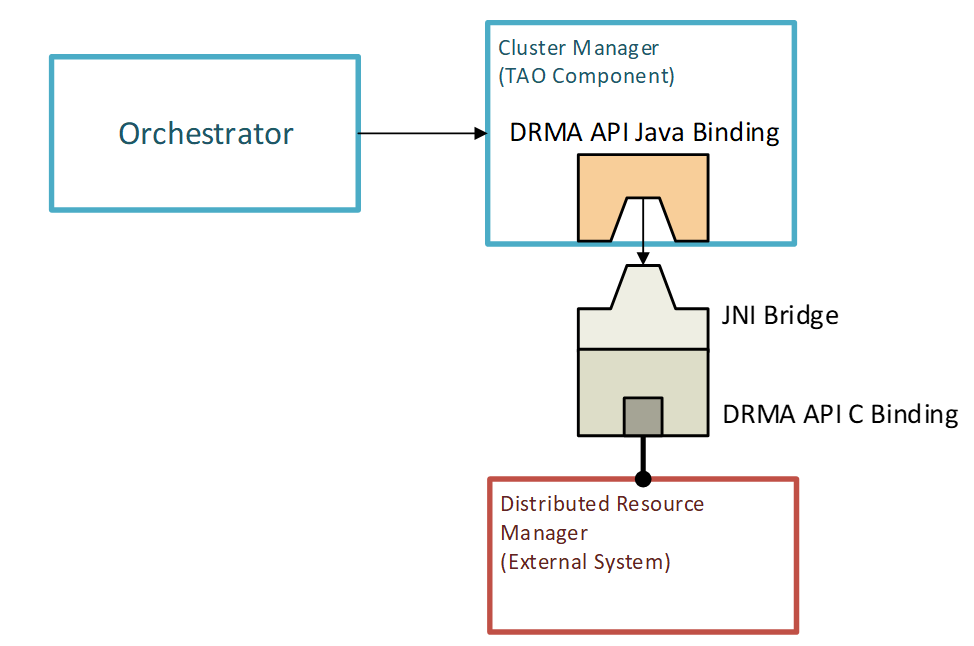 TAO Integration of a DRM system
TAO Integration of a DRM system
The swap of DRM bridge implementations is possible by the usage the Java Service Provider Interface (SPI).
The dynamic allocation of computing resources (virtual machines) is done via the OpenStack Nova API. OpenStack is a cloud resources management software currently in use in most of the cloud providers. It exposes many APIs, the Nova subset being the computing-related API. TAO has a dedicated module that makes use of this API.
xcube#
All services proposed here will be run and orchestrated by a Kubernetes (K8s) Engine operating in the cloud environment. Cube computations are performed on a dedicated cluster using containerised xcube AVL Runtime. The compute power for the distributed chunk computations comes from a dedicated Dask cluster that is also maintained and scaled through K8s. The following diagram illustrates the design described above.
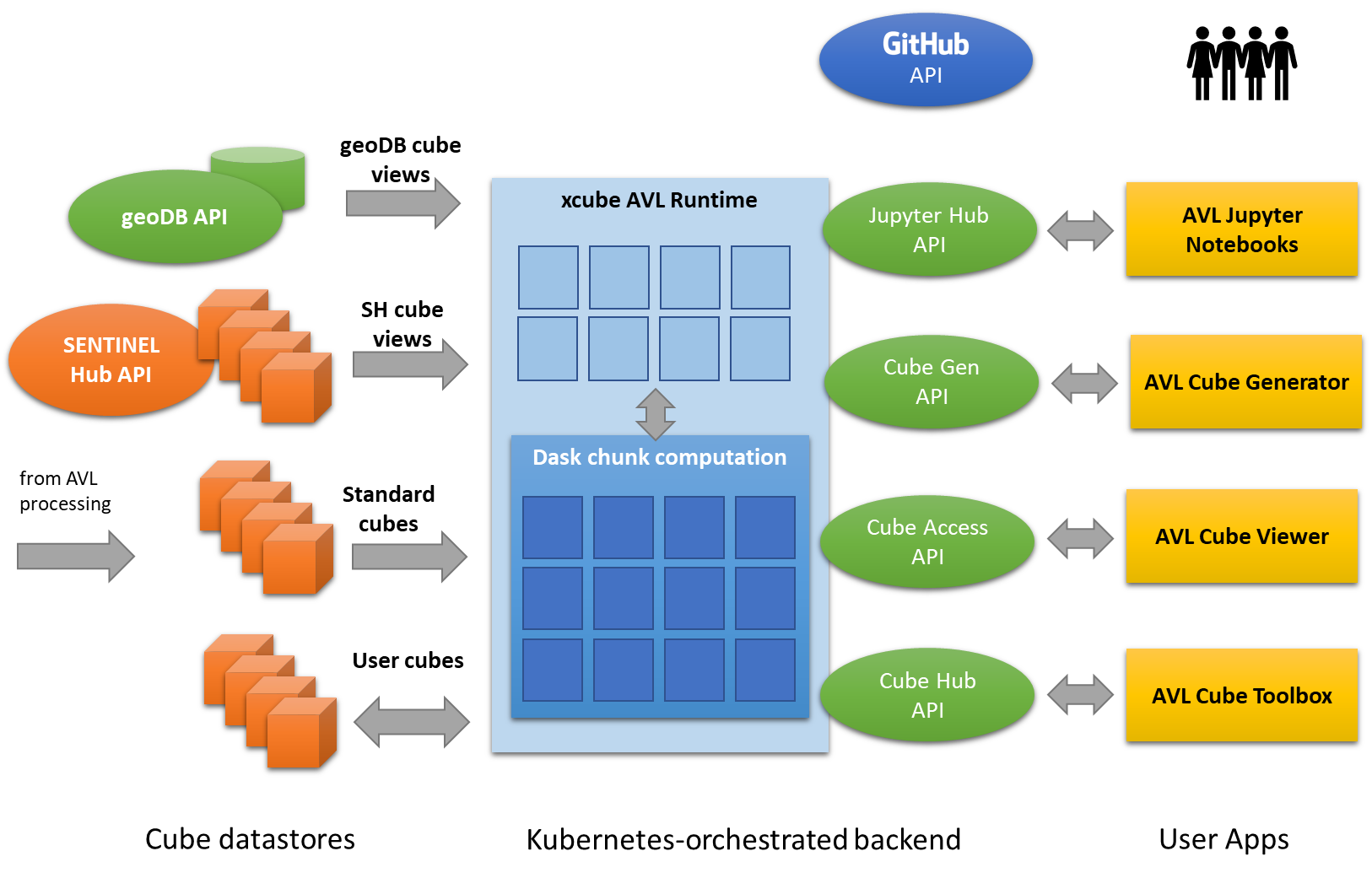 Concurrent computations in the AVL Exploitation subsystem
Concurrent computations in the AVL Exploitation subsystem
Long Lifetime Software#
AVL uses the following software resources:
| Software resource | Minimal Version | Reference |
|---|---|---|
| Spring Framework | 5.2.0 .RELEASE | link |
| Java SE | 8u131 | link |
| PostgreSQL | 11 | link |
| Docker Community Edition | 17.03 | link |
| HTML5 | link | |
| jsPlumb Community Edition | 2.4.2 | link |
| jQuery | 3.2.1 | link |
| Orfeo Toolbox | 7.2.0 | link |
| SNAP | 8.0.0 | link |
| GDAL | 3.2.0 | link |
AVL software resources
The target operating system for AVL shall be Ubuntu 20.04.